Ce projet vise à déterminer les emplacements optimaux des postes de police à Nantes afin de réduire les temps d’intervention des forces de l’ordre en cas d’incidents. Pour ce faire, une modélisation basée sur l’analyse des zones sensibles (hotspots) de criminalité a été réalisée. Deux approches ont été explorées : le problème des p-centres, qui minimise la distance maximale entre les incidents et les postes, et le Location Set Covering Problem (LSCP), qui optimise la couverture spatiale en garantissant un temps de réponse acceptable. Cette étude utilise des données géographiques issues d'OpenStreetMap et des statistiques locales de criminalité pour créer des scénarios de simulation réalistes, et s’appuie sur des algorithmes de clustering pour améliorer l’efficacité des calculs. Le projet propose ainsi une méthodologie innovante permettant aux décideurs d’améliorer la sécurité publique de manière pragmatique et efficace.
1. Introduction
Si la ville de Nantes était autrefois reconnue pour son cadre de vie agréable, son image s’est récemment assombrie en raison d’événements violents survenus dans certains quartiers prioritaires (meurtres par arme à feu) et d’agressions sexuelles en centre-ville. Même si les statistiques confirment que la criminalité n’y est pas nécessairement plus élevée que dans des agglomérations comparables, l’opinion publique demeure sensible à ces faits divers, et les politiques de sécurité locales se sont durcies.
Cette perception contrastée — entre réalité statistique et sentiment d’insécurité — a conduit à la publication de nombreuses données sur les actes de délinquance, offrant ainsi une base solide pour mener des analyses spatiales et des simulations.
2. Définition des termes et choix de modélisation
Pour notre étude, nous avons choisi de caractériser et de spatialiser les événements malveillants à travers le concept de hotspot. En criminologie, un hotspot est généralement défini comme une zone géographique où la fréquence des délits est significativement plus élevée qu’ailleurs (Braga, 2005). Cette notion repose sur la théorie selon laquelle un petit nombre de lieux concentre un grand volume d’actes criminels (Sherman, Gartin & Buerger, 1989). Les travaux empiriques de Weisburd (2015) ont par exemple montré qu’environ 50 % des appels liés aux crimes violents peuvent se concentrer sur moins de 5 % de l’espace urbain.
S’inscrivant dans cette logique, la police prédictive (Perry et al., 2013) repose largement sur l’identification de hotspots pour guider les patrouilles et intervenir de façon proactive. Plutôt que de modéliser des agents « délinquants » et « victimes » interagissant dans l’espace, nous avons opté pour une approche simplifiée :
- Chaque hotspot est un nœud où se déclenchent des incidents selon une liste prédéfinie d’infractions.
- Les patrouilles reçoivent une alerte et se déplacent vers le hotspot pour intervenir.
Cette simplification présente plusieurs avantages pour notre étude, orientée sur l’optimisation de la couverture spatiale :
- D’une part, cela est plus simple à mise en œuvre : Cette approche évite d’introduire des règles complexes concernant les déplacements ou interactions des acteurs criminels. La charge criminelle est directement localisée sur des points fixes, les hotspots.
- D’autre part, cela permet de prendre en compte la concentration spatiale : Inspirée par la Routine Activity Theory (Cohen & Felson, 1979), selon laquelle les crimes surviennent lorsque trois conditions sont réunies — un délinquant motivé, une cible accessible et l’absence de surveillance —, et par les travaux sur les hotspots (Sherman et al., 1989 ; Weisburd, 2015), elle met l’accent sur le fait que la majorité des délits se concentrent dans un ensemble limité de lieux.
Enfin, elle permet une focalisation sur le temps de réponse : L’approche permet de mesurer directement le délai nécessaire à une patrouille pour rejoindre un hotspot, sans se disperser sur l’étude des processus comportementaux ou des motivations à l’origine des incidents.
Ainsi, les hotspots sont considérés comme des sources directes d’infractions, permettant de se concentrer sur la logique territoriale du phénomène moins essentialiste :
- Le temps d’intervention varie-t-il en fonction de la configuration spatiale des postes ?
- La résolution des incidents diffère-t-elle selon la distribution spatiale des postes ?
Ce choix de modélisation, qui privilégie l’identification des hotspots à la simulation des comportements criminels individuels, permet de maintenir un modèle plus épuré, centré sur l’efficacité du dispositif policier et sur l’analyse de la distribution spatiale des incidents dans la ville.
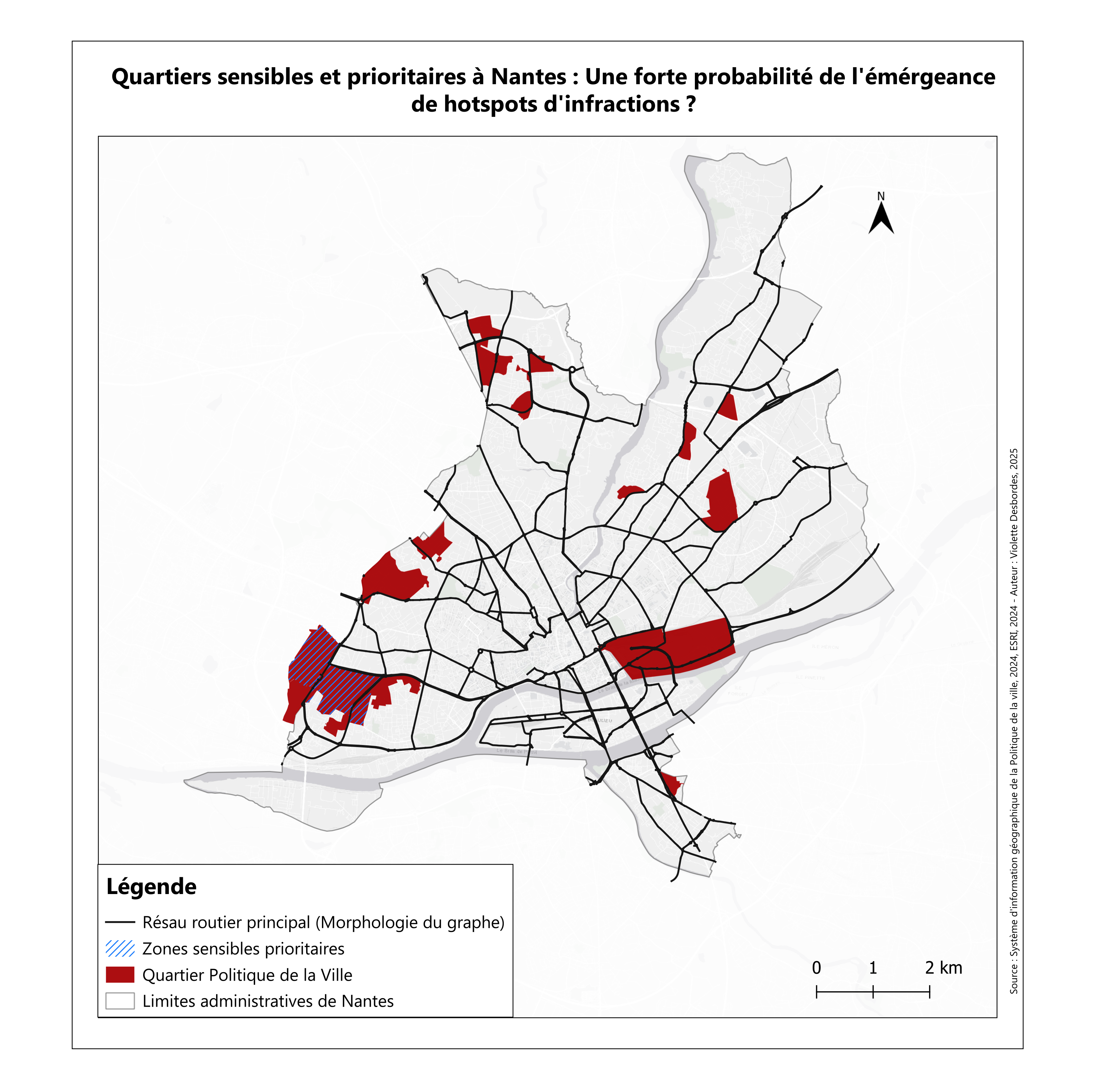
Quartiers sensibles et prioritaires à Nantes : Une forte probabilité d’émergence de hotspots d’infraction.
Cette carte a pour objectif d’expliquer nos choix dans l’identification des emplacements où les hotspots d’infractions ont le plus de chances d’émerger dans la ville de Nantes. En croisant les données des Zones de Sécurité Prioritaires (ZSP) et des Quartiers Prioritaires de la Politique de la Ville (QPV), nous avons supposé que les faits de délinquance étaient plus susceptibles de se concentrer dans ces zones sensibles.
Bien que cette approche soit relativement déterministe et ne reflète pas pleinement la complexité de la réalité, elle offre un point de départ cohérent pour la création des hotspots. Ces zones, toutes connectées au réseau routier principal, permettent d’orienter notre modélisation vers des scénarios plus réalistes et opérationnels.
3. Problématisation
Dans ce contexte, la question centrale de notre sujet est la suivante : Quels sont les emplacements optimaux de n postes de police, qui permettent de réduire les temps d’intervention des forces de l’ordre face aux incidents ?
Deux grandes approches de la recherche opérationnelle peuvent être mobilisées :
- Le problème des p-centres, qui consiste à localiser p installations (ici, des postes de police) de manière à minimiser la distance maximale séparant un hotspot criminel d’un poste.
- Le LSCP (Location Set Covering Problem), qui fixe un rayon de couverture acceptable (distance maximale à ne pas dépasser) et cherche le nombre minimal de postes nécessaires pour couvrir chaque zone sensible.
Nous avons choisi de privilégier le LSCP (Location Set Covering Problem), car il donne une vision claire de la manière de garantir une intervention rapide partout (chaque point restant à une distance raisonnable). Toutefois, nous avons également exploré le problème des p-centres, qui est le plus pertinent dans un cadre réaliste où les contraintes économiques peuvent imposer un nombre donné d’infrastructures.
Cependant, en raison de la complexité algorithmique et du temps de calcul très long des p-centres — chaque point client nécessitant un calcul exhaustif — nous avons opté pour une approche de clustering (Clustering Algorithms: K-means) afin de réduire les temps de calcul.
Pour cela, l’espace de Nantes a été divisé en 100 clusters, ce qui a permis de restreindre les calculs à des sous-ensembles plus petits et ainsi, améliorer la vitesse d’exécution.
Néanmoins, cette approche introduit une perte de précision, car les clusters limitent la possibilité d’optimiser la localisation globale des infrastructures en considérant simultanément l’ensemble des points clients.
4. Hypothèse et méthodologie
Notre hypothèse de recherche postule que : Réduire le rayon de couverture d au sein du modèle LSCP (Location Set Covering Problem) améliore significativement la réactivité des forces de l’ordre, en garantissant un temps de réponse plus court pour la majorité des incidents.
Autrement dit, imposer une distance maximale plus restrictive – et donc potentiellement installer davantage de postes – devrait se traduire par un pourcentage plus élevé d’interventions réalisées dans le délai ciblé.
Pour valider ou infirmer cette hypothèse, notre méthode consiste à faire varier le paramètre d sur plusieurs scénarios de simulation, comme par exemple :
- Scénario A : d = 30 minutes, conduisant à un certain nombre de postes calculé via LSCP.
- Scénario B : d = 15 minutes, avec un nombre de postes sans doute plus important, mais une distance maximale autorisée plus faible.
- Scénario C : d = 5 minutes, renforçant encore la contrainte de couverture et augmentant possiblement le nombre de postes requis.
Dans chaque scénario, la configuration spatiale des postes obtenue par LSCP est intégrée à la modélisation multi-agents qui apporte une considération dynamique : Des incidents sont générés de manière aléatoire (les actes violents ont plus de chance de se produire dans les zones sensibles (40%)), et des patrouilles se déplacent depuis les postes les plus proches pour y intervenir. Les indicateurs clés (temps moyen d’intervention, pourcentage d’incidents traités sous un seuil temporel, etc.) seront ensuite comparés entre les trois scénarios.
Ainsi, si un scénario avec un rayon d plus réduit aboutit effectivement à un temps de réponse plus court et une couverture plus efficace (nombre d’incidents résolus dans le délai ciblé plus élevé), notre hypothèse sera confirmée. Dans le cas contraire, ou si l’apport de scénarios très contraints (faible d) reste marginal, l’hypothèse devra être nuancée ou révisée.

Illustration des scénarios de simulation LSCP selon différents rayons de couverture.
5. Techniques et outils
Choix du langage
Nous avons décidé de développer entièrement le projet en Julia, qui se distingue des autres langages (comme Python) par son haut niveau de performance et sa facilité d’écriture. Elle permet d’écrire du code concis, lisible, tout en bénéficiant d’exécutions rapides presque au niveau du C/C++. Dans un projet mêlant optimisation (LSCP) et simulation multi-agents (ABM), la vitesse de calcul est indispensable pour traiter de grandes quantités de données.
De plus, Julia dispose de bibliothèques spécialisées (JuMP pour l’optimisation, Agents.jl pour l’ABM) qui offrent un écosystème cohérent et performant, simplifiant la mise en place de scénarios complexes.
Création du graphe à partir du réseau routier d’OpenStreetMap
Pour construire la représentation spatiale du réseau urbain, notre choix s’est porté sur OpenStreetMap (OSM). En effet, OSM fournit un réseau routier orienté, c’est-à-dire que les routes ne sont pas toujours bidirectionnelles (sens unique, par exemple, où A → B ≠ B → A).
De plus, les tags de vitesse (maxspeed) associés aux tronçons de route permettent de pondérer chaque arête du graphe en fonction du temps de trajet plutôt que de la seule distance kilométrique linéaire. Cet aspect nous a paru indispensable pour modéliser le temps de réponse des patrouilles de police.
Aussi, cela permet de générer un graphe routier qui correspond davantage à la réalité quotidienne des déplacements : il ne s’agit pas simplement d’un réseau « idéal » où tous les arcs seraient bidirectionnels et de vitesse uniforme, mais d’un modèle un peu plus complexe qui intègre des restrictions directionnelles et des limites de vitesse. Cela donne une meilleure estimation du temps nécessaire pour qu’une patrouille rejoigne un hotspot criminel, et donc une analyse plus réaliste de la couverture spatiale assurée par les postes de police.
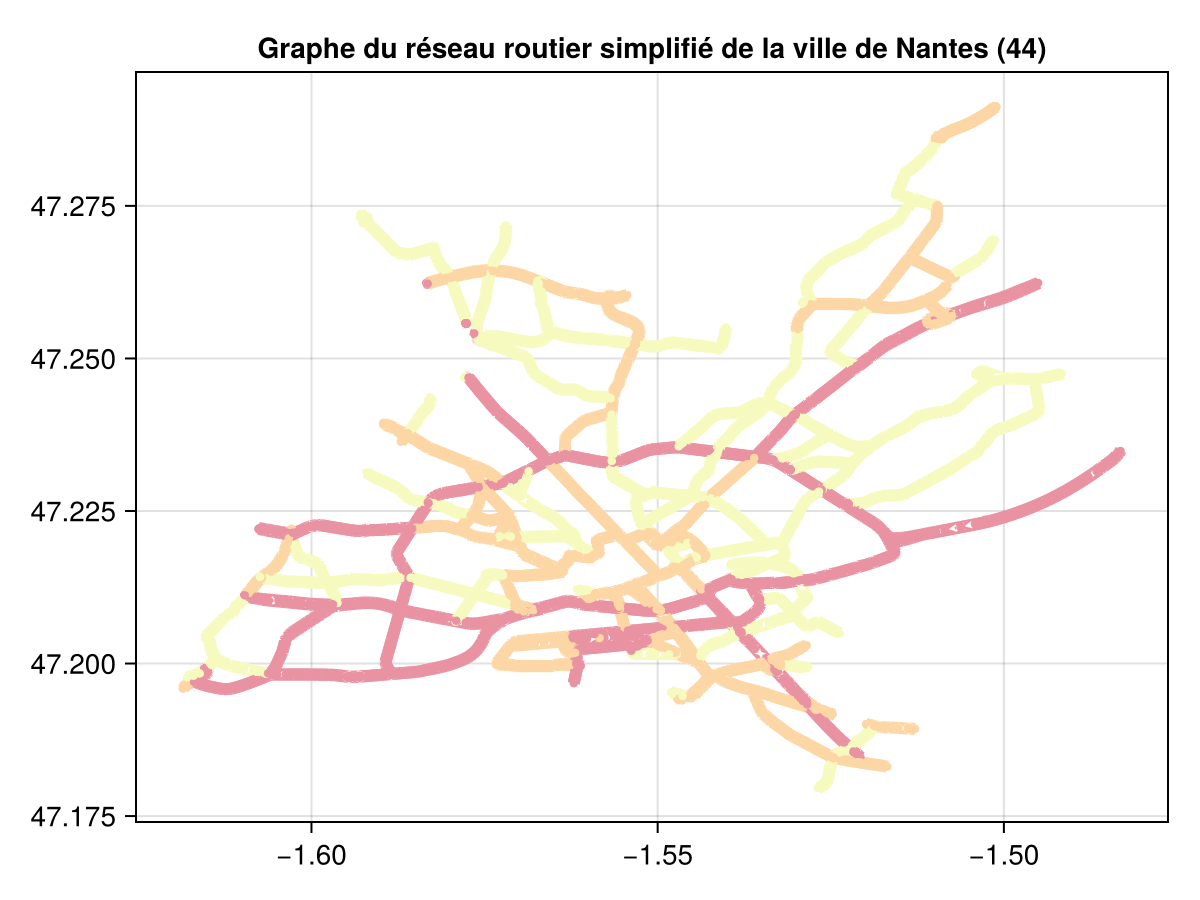
Graphe du réseau routier simplifié de la ville de Nantes (44).
Afin d’éviter des temps de calcul interminables, nous avons simplifié le réseau routier aux trois grandes types de routes : Primary, Secondary et Tertiary (voir la figure ci-dessus).
Création de la population virtuelle
Répartition des incidents
La population virtuelle repose sur les données statistiques locales, notamment la répartition des infractions observées à Nantes. Avec 65 % des incidents que nous considérons comme non violents et 35 % comme violents, nous avons généré une liste d’infractions correspondant à ces proportions. Ces données incluent des types spécifiques de crimes (vols, violences sexuelles, dégradations, etc.).
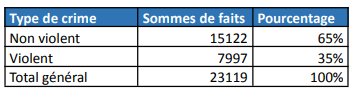
Pourcentage des types de crime dans la ville de Nantes. Source : Ministère de l’Intérieur.
Points clients et hotspots
Dans le cadre du modèle p-centre, les points clients, qui représentent des lieux où des incidents pourraient survenir, sont répartis initialement de manière équilibrée sur tout le territoire. Cette approche garantit une couverture spatiale homogène pour les premières simulations. Une fois que les incidents commencent à émerger, ils forment des hotspots. Ces derniers deviennent alors eux-mêmes des points clients pour les simulations suivantes. Cela permet une adaptation progressive des infrastructures policières à la dynamique spatiale des incidents.
En revanche, pour le modèle LSCP, il n’y a pas de notion de point client à proprement parler mais un calcul de matrice de distance-temps, calculée à partir du réseau routier. Ici, les hotspots n’interviennent pas directement, car l’objectif est de minimiser le temps maximal d’intervention à tout point du graphe en optimisant la répartition des infrastructures.
Modélisation des patrouilles de police
Les patrouilles de police, quant à elles, permettent d’évaluer la capacité opérationnelle du dispositif. Chaque patrouille est initialement assignée à un poste de police et se déplace en fonction des incidents signalés dans les hotspots. Ces déplacements sont simulés à l’aide des données du réseau routier, pondérées par les limitations de vitesse et les contraintes du réseau (graphe orienté).
Dans le modèle p-centre, les patrouilles sont déployées pour minimiser la distance maximale entre les postes et les points clients. Concernant le LSCP, elles sont utilisées pour tester la capacité des postes à garantir une intervention dans une durée prédéterminée, souvent mesurée en minutes.
Tableau des méthodes et fonctions utilisées
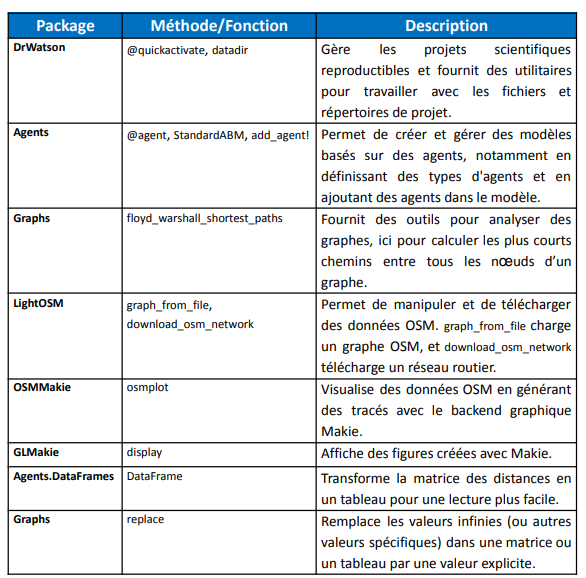
Tableau des méthodes et fonctions utilisées dans notre étude.
6. Résultats
[Insérez ici les résultats obtenus lors des différentes simulations. Ces résultats peuvent inclure des graphiques, des comparaisons de temps d’intervention, et des tableaux de performance selon les différents scénarios.]
Illustration des résultats obtenus lors des simulations.
7. Conclusion et discussion
Pour rappel, notre problématique était la suivante :
Quels sont les emplacements optimaux de n postes de police, qui permettent de réduire les temps d’intervention des forces de l’ordre face aux incidents ?
Pour y répondre, nous avons utilisé deux approches opérationnelles :
- Le problème des P-Centres : Cette approche permet, à partir d’une contrainte de n postes de police, de trouver leur emplacement idéal pour minimiser le temps de réponse.
- Le LSCP (Location Set Covering Problem) : Cette méthode permet de trouver le nombre idéal de postes de police et leur position pour couvrir l’espace en un seuil d de distance-temps.
Ces deux axes permettent d’aborder la question sous deux angles différents :
- La contrainte économique : Construire un poste coûte cher, donc l’objectif est de minimiser les coûts tout en assurant un service optimal.
- La contrainte temporelle : Plus la contrainte temporelle est forte (réduire le temps d’intervention), plus le nombre de postes nécessaires sera élevé.
8. Bibliographie
- Braga, A. (2005). Hot spots policing and crime prevention: A systematic review of randomized controlled trials. Journal of Experimental Criminology, 1(3), 317–342.
- Cohen, L. E., & Felson, M. (1979). Social change and crime rate trends: A routine activity approach. American Sociological Review, 44(4), 588–608.
- Perry, W. L., McInis, B., Price, C. C., Smith, S. C., & Hollywood, J. S. (2013). Predictive Policing: The Role of Crime Forecasting in Law Enforcement Operations. RAND Corporation.
- Sherman, L. W., Gartin, P. R., & Buerger, M. E. (1989). Hot spots of predatory crime: Routine activities and the criminology of place. Criminology, 27(1), 27–55.
- Weisburd, D. (2015). The law of crime concentration and the criminology of place. Criminology, 53(2), 133–157.
- Weisburd, D., & Eck, J. E. (2004). What Can Police Do to Reduce Crime, Disorder, and Fear? The Annals of the American Academy of Political and Social Science, 593(1), 42–65.

